Extractors
Extractors are used for structured extraction from un-structured data of any modality. For example, line items of an invoice as JSON, objects in a video, embedding of text in a PDF, etc.
Extractor Input and Output
Extractors consume Content which contains raw bytes of unstructured data, and they produce a list of Content and features from them.
For example, a PDF document could be broken down to - images, multiple text chunks, tabular data encoded as JSON, embeddings of the text chunks, each would be encoded as a Content and emitted by the extractor. Indexify stores raw bytes into blob store and features such as embeddings or JSON documents into indexes for retrieval.
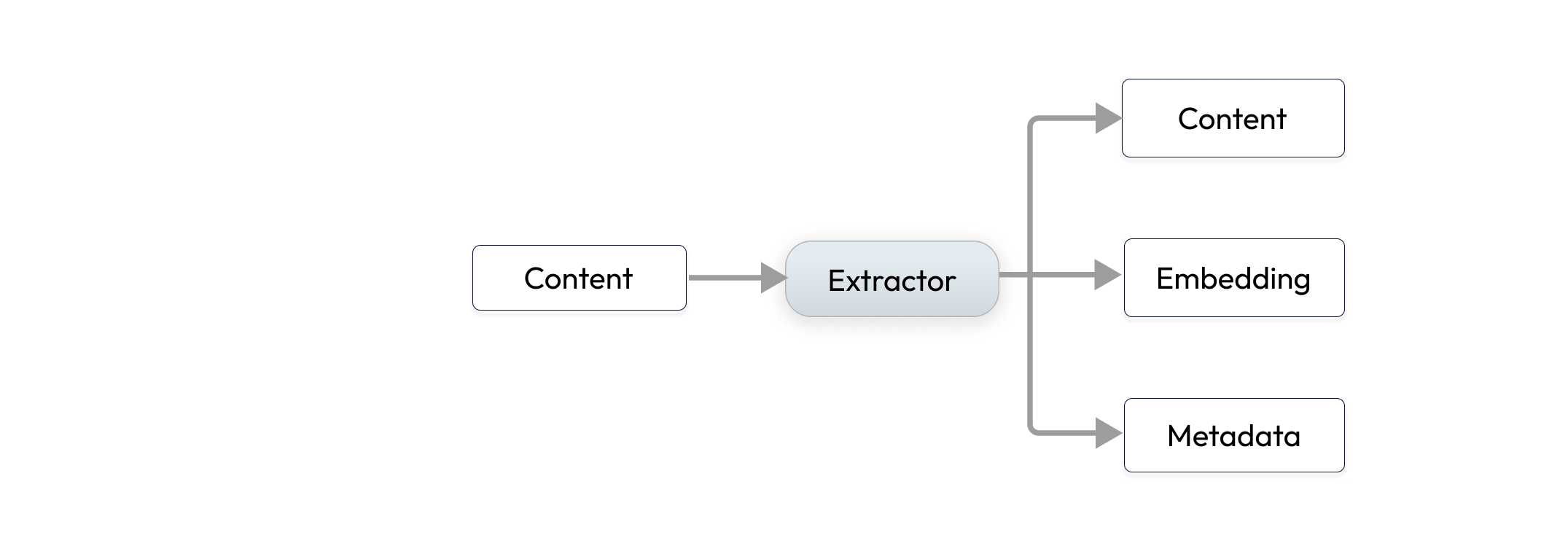
Extractors are typically built using AI model and some additional pre and post processing of content.
Install the SDK
The tools to build, test and package extractors are available through the Python package indexify-extractor-sdk. A typescript SDK is under development also.
Running Extractors
Running extractor locally
This will invoke the extractor inextractor_file.py and create a Content with hello world as the data.
If you want to pass in the contents of a file into the payload use --file </path/to/file>
Running the extractor to continuously extract ingested content
You can run the extractor as a long running process to continuously receive stream of content and extract them from the Indexify control plane. You can run as many instances of the extractors you want and achieve scalability.
The addresses here can be found from Indexify server's configuration.From Packaged Containers
Extractors can be deployed in production with ease using docker along with Indexify server in a cluster. You can test an extractor packaged with docker by running docker locally.
Passing a local file from your laptop to docker requires bind-mounting the file into the container
docker run -v /path/to/local/file:/tmp/image.jpg tensorlake/yolo-extractor run-local yolo_extractor:YoloExtractor --file /tmp/image.jpg
EXTRACTOR_PATH