Effortless Ingestion and Extraction for AI Applications at Any Scale
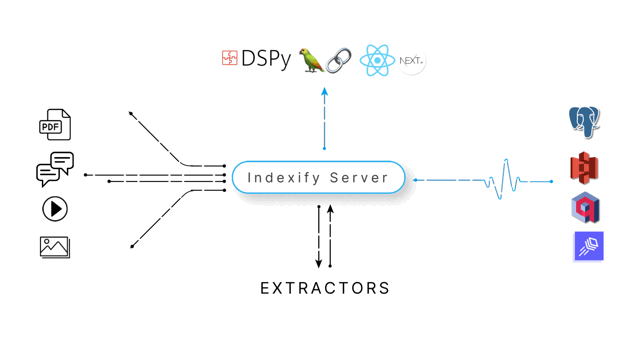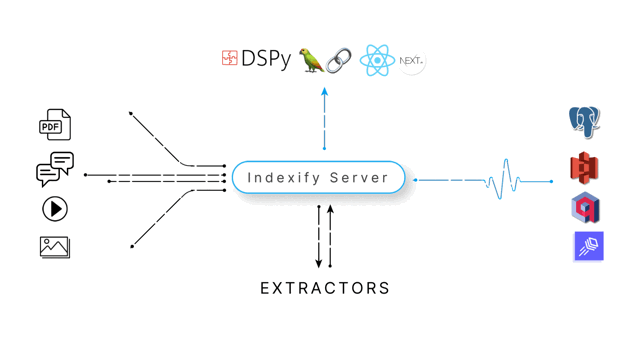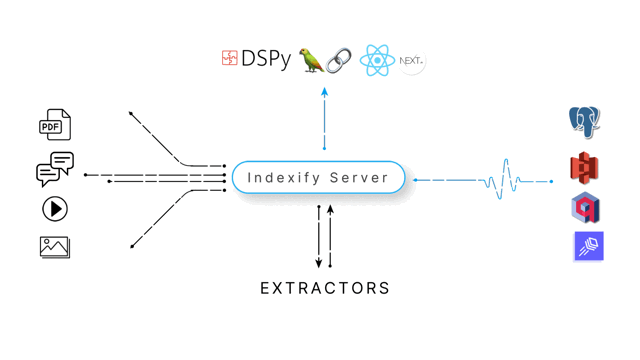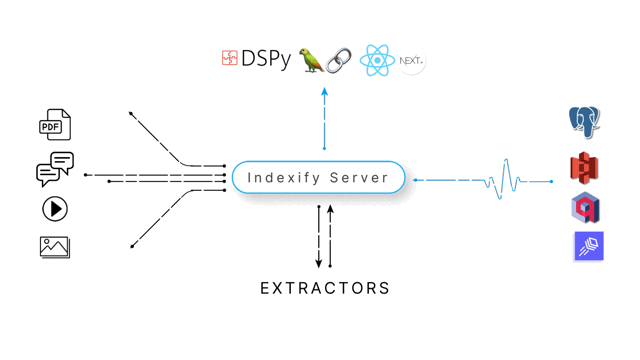
Indexify is a data framework designed for building ingestion and extraction pipelines for unstructured data. These pipelines are defined using declarative configuration. Each stage of the pipeline can perform structured extraction using any AI model or transform ingested data. The pipelines start working immediately upon data ingestion into Indexify, making them ideal for interactive applications and low-latency use cases.
You should use Indexify if -
- You are working with non-trivial amount of data, >1000s of documents, audio files, videos or images.
- The data volume grows over time, and LLMs need access to updated data as quickly as possible
- You care about reliability and availability of your ingestion pipelines.
- You are working with multi-modal data, or combine multiple models into a single pipeline for data extraction.
- User Experience of your application degrades if your LLM application is reading stale data when data sources are updated.
Why use Indexify?
Most LLM data frameworks for unstructured data are primarily optimized for prototyping applications. A typical MVP data processing pipeline is written as follows -
data = load_data(source)
embedding = generate_embedding(data)
structured_data = structured_extraction_function(data)
db.save(embedding)
db.save(structured_data)
The Indexify Approach
Indexify provides a declarative configuration approach. You can translate the code above into a pipeline like this,
name: 'pdf-ingestion-pipeline'
extraction_policies:
- extractor: 'tensorlake/markdown'
name: 'pdf_to_markdown'
- extractor: 'tensorlake/ner'
name: 'entity_extractor'
content_source: 'pdf_to_markdown'
- extractor: 'tensorlake/minilm-l6'
name: 'embedding'
content_source: 'pdf_to_markdown'
-
Data extraction/transformation code are written as an
Extractorand referred in any pipelines. Extractors are just functions under the hood that take data from upstream source and spits out transformed data, embedding or structured data. -
The extraction policy named
pdf_to_markdownconverts every PDF ingested into markdown. The extraction policies,entity_extractorandpdf_to_markdownare linked topdf_to_markdownusing thecontent_sourceattribute, which links downstream extraction policies to upstream. -
We have written some ready to use extractors. You can write custom extractors very easily to add any data extraction/transformation code or library.
Indexify is distributed on many machines to scale-out each of the stages in the above pipeline. The pipeline state is replicated across multiple machines to recover from hardware failures, software crashes of the server. You get predictable latencies and throughput for data extraction, and it's fully observable to help troubleshoot.
Local Experience
Indexify runs locally without any dependencies. The pipelines developed and tested on laptops can run unchanged in production.
Start Using Indexify
Dive into Getting Started to learn how to use Indexify.
If you would like to learn some common use-cases -
- Learn how to build ingestion and extraction pipelines for RAG Applications
- Extract PDF, Videos and Audio to extract embedding and structured data.
Features
- Makes Unstructured Data Queryable with SQL and Semantic Search
- Real Time Extraction Engine to keep indexes automatically updated as new data is ingested.
- Create Extraction Graph to create multi-step workflows for data transformation, embedding and structured extraction.
- Incremental Extraction and Selective Deletion when content is deleted or updated.
- Extractor SDK allows adding new extraction capabilities, and many readily available extractors for PDF, Image and Video indexing and extraction.
- Multi-Tenant from the ground up, Namespaces to isolate sensitive data.
- Works with any LLM Framework including Langchain, DSPy, etc.
- Runs on your laptop during prototyping and also scales to 1000s of machines on the cloud.
- Works with many Blob Stores, Vector Stores and Structured Databases
- We have even Open Sourced Automation to deploy to Kubernetes in production.